Config Settings in Pega PRPC version 6 and above:
Please find the sample config xml tags (prconfig.xml), if any specification need to do for some particular nodes alone.
In this post, we will see few of the tags used in our application, had added explainations which I know. Remaining tags we will review in next upcoming posts.
Please add if you have any settings which is not given below and usage of its. It will be helpful for understanding.
<!-- All the config settings are explained in details for pega 6.2 version, but still the same config settings can be used in 7.1 also, Updated versions are yet to get, if any one get the updated, please share the link in comments, it will be helpful for all.
https://community.pega.com/knowledgebase/documents/configuration-settings-reference-guide-prpc-5x-prpc-62
-->
<?xml version="1.0" encoding="UTF-8" ?>
<pegarules>
<!-- system name which you wanted to give -->
<env name="identification/systemName" value="CustomSystemName" />
<env name="identification/cluster/public/address" value="169.254.169.254" />
<env name="initialization/persistRequestor" value="OnTimeout" />
<env name="initialization/useNativeLibrary" value="true" />
<env name="initialization/explicitTempDir" value="${pega.tmpdir}" />
<env name="initialization/explicittempdir" value="/amp/apps/tcpegaewf00/properties/explicitTempDir"/>
<env name="initialization/displayExceptionTraceback" value="false" />
<env name="initialization/persistrequestor/usepagelevelpassivation" value="false" />
<env name="initialization/passivationinterval" value="7200"/>
<env name="initialization/ContextRewriteEnabled" value="true"/>
<env name="initialization/SetBaseHTMLContext" value="https://eworkflow.ampf.com/prweb"/>
<env name="initialization/preloadengineclasses" value="com.pega.pegarules.priv.util.StackTrace com.pega.apache.log4j.spi.ThrowableInformation"/>
<!-- As of 6.1 SP2, settings are available in the database but are not yet the default -->
<env name="initialization/settingsource" value="file" />
<env name="initialization/settingsource" value="merged" />
<env name="authentication/trojanhorseprotection" value="1"/>
<env name="diagnostic/clipboard/pageNamesToTrace" value="CTIPhone" />
<!--for setting time out for the application -->
<env name="timeout/application" value="14400" />
<env name="timeout/browser" value="14400" />
<env name="timeout/portlet" value="9000" />
<env name="timeout/thread" value="7200"/>
<env name="timeout/page" value="7200"/>
<!--HTTP related config settings -->
<env name="HTTP/SetSecureCookie" value="true" />
<!-- AES related config-->
<env name="management/enabled" value="true" />
<env name="management/interval" value="120" />
<env name="management/notifications/appender" value="ALERT-AES-SOAP" />
<!-- use the following entry to specify resource adapter logging level at startup,
acceptable values: SEVERE,WARN,INFO,CONFIG,FINE,FINER,FINEST
-->
<env name="pradapter/loggingLevel" value="INFO" />
<env name="agent/enable" value="true" />
<env name="initServices/initEmail" value="true" />
<env name="initServices/initFile" value="true" />
<env name="initServices/initJMS" value="true" />
<env name="initServices/initMQ" value="true" />
<env name="initservices/initmq/pollers" value="true" />
<!--Tracer related config settings:
You can adjust the buffer size of the Tracer header to increase the limit for unprocessed events. By default, the system saves up to 50,000 items for unprocessed events during a Tracer operation. If the buffer exceeds this limit, Tracer processing ends.
-->
<env name="tracer/queue/type" value="file"/>
<env name="tracer/queue/file/limit" value="nnnn"/>
<env name=" tracer/queue/header/limit" value="nnnnn"/>
<!-- Database related config settings -->
<env name="database/storageVersion" value="6" />
<env name="database/databases/PegaRULES/dataSource" value="java:comp/env/jdbc/PegaRULES"/>
<env name="database/databases/PegaDATA/dataSource" value="java:comp/env/jdbc/PegaRULES"/>
<env name="alerts/database/acquireConnectionAlertMS" value="200" />
<env name="database/transactionalLockManagement" value="Standard" />
<env name="database/baseTable/name" value="pr4_base" />
<!-- One database instance can support multiple separate systems that use distinct schemas. The prconfig.xml file for each system must correctly identify the schema to use.
-->
<env name="database/baseTable/schema" value="schema name" />
<env name="database/drivers" value="com.microsoft.sqlserver.jdbc.SQLServerDriver;oracle.jdbc.OracleDriver" />
<env name="database/databases/PegaRULES/url" value="jdbc:sqlserver://serverName:1433;SelectMethod=cursor;SendStringParametersAsUnicode=false" />
<env name="database/databases/PegaRULES/userName" value="a_username" />
<env name="database/databases/PegaRULES/password" value="a_password" />
</pegarules>
Sunday, April 28, 2019
Wednesday, April 10, 2019
Logging in Pega PRPC - Part 2
Logging in Pega PRPC - Part 2
In this blog, we will see about logging the pega rules in log file for debugging purpose. But once debugging is done, it should be removed, else performance of the application will be bad.
How this can be achieved, has been given in detail in the pega PDN link below:
https://community.pega.com/knowledgebase/articles/log-customization-prloggingxml-file#capture
From the above link we had taken small part, which is logging the rules.
By Adding the below format in the prlog4j2.xml file in 7.3 version and out of the log file will be as shown below:
Sample format in the XML:
Under loggers object, you need to add this logger tag name.
name will be the rule type,which we need to trace or debug, but it should be given in java class.
The format for the Pega 7 Platform Java class instances is a three-part name, separated by periods.
If the final portion of the name was omitted (Rule_Obj_Activity.Validate), then messages for all Validate activities would print out, regardless of in what class they were defined. Likewise, if developers are interested in printing out messages for all Activities, they should use the first part of the reference (Rule_Obj_Activity), to get all messages for activities.
<Loggers>
<Logger name="Rule_Obj_Activity" additivity="false" level="info">
<AppenderRef ref="PEGA"/>
</Logger>
<Logger name="Rule_Obj_Model.pyDefault" additivity="false" level="info">
<AppenderRef ref="PEGA"/>
</Logger>
</Loggers>
Sample log file generated:
2019-04-10 23:14:45,091 [http-nio-8080-exec-3] [ STANDARD] [ ] [ VISA:01.01.01] (Rule_Obj_Activity.Invoke.Rule_Connect_REST.Action) INFO localhost|0:0:0:0:0:0:0:1 Author.VISA - Starting remote service invocation...
2019-04-10 23:14:50,048 [http-nio-8080-exec-3] [ STANDARD] [ ] [ VISA:01.01.01] (Rule_Obj_Activity.Invoke.Rule_Connect_REST.Action) INFO localhost|0:0:0:0:0:0:0:1|Rule-Connect-REST.Pega-Int-PDN-Rss.pyRSSConnectService Author.VISA - Finished remote service invocation
Above log file has been generated, when Rule_Obj_Activity.Invoke.Rule_Connect_REST.Action this activity is called during execution.
In this blog, we will see about logging the pega rules in log file for debugging purpose. But once debugging is done, it should be removed, else performance of the application will be bad.
How this can be achieved, has been given in detail in the pega PDN link below:
https://community.pega.com/knowledgebase/articles/log-customization-prloggingxml-file#capture
From the above link we had taken small part, which is logging the rules.
By Adding the below format in the prlog4j2.xml file in 7.3 version and out of the log file will be as shown below:
Sample format in the XML:
Under loggers object, you need to add this logger tag name.
name will be the rule type,which we need to trace or debug, but it should be given in java class.
The format for the Pega 7 Platform Java class instances is a three-part name, separated by periods.
- The leftmost part refers to whether the object in question is an activity, a when rule, or a model. The name refers to the class of those objects: Rule-Obj-Activity, Rule-Obj-When, or Rule-Obj-Model, with underscores instead of hyphens.
- The middle portion of the reference is the actual name of the object (the activity, when block, or model).
- The final portion of the reference is the class on which the activity, when or model is defined. For the example above, the reference would be: Rule_Obj_Activity.Validate.Work_General
If the final portion of the name was omitted (Rule_Obj_Activity.Validate), then messages for all Validate activities would print out, regardless of in what class they were defined. Likewise, if developers are interested in printing out messages for all Activities, they should use the first part of the reference (Rule_Obj_Activity), to get all messages for activities.
<Loggers>
<Logger name="Rule_Obj_Activity" additivity="false" level="info">
<AppenderRef ref="PEGA"/>
</Logger>
<Logger name="Rule_Obj_Model.pyDefault" additivity="false" level="info">
<AppenderRef ref="PEGA"/>
</Logger>
</Loggers>
Sample log file generated:
2019-04-10 23:14:45,091 [http-nio-8080-exec-3] [ STANDARD] [ ] [ VISA:01.01.01] (Rule_Obj_Activity.Invoke.Rule_Connect_REST.Action) INFO localhost|0:0:0:0:0:0:0:1 Author.VISA - Starting remote service invocation...
2019-04-10 23:14:50,048 [http-nio-8080-exec-3] [ STANDARD] [ ] [ VISA:01.01.01] (Rule_Obj_Activity.Invoke.Rule_Connect_REST.Action) INFO localhost|0:0:0:0:0:0:0:1|Rule-Connect-REST.Pega-Int-PDN-Rss.pyRSSConnectService Author.VISA - Finished remote service invocation
Above log file has been generated, when Rule_Obj_Activity.Invoke.Rule_Connect_REST.Action this activity is called during execution.
Tuesday, April 9, 2019
Logging in Pega PRPC
Logging in Pega PRPC:
Logging is an important component of the software development.
A well-written logging code offers quick debugging, easy maintenance, and structured storage of an application's runtime information.
By default pega had configured Log4J for logging.
Details about the components is explained in PDN link:
https://community.pega.com/knowledgebase/articles/log-customization-prloggingxml-file#capture
Log4j artchitecture you can read it from the below URL:
https://www.tutorialspoint.com/log4j/log4j_quick_guide.htm
More details of the prlogging.xml structure is well explained in the apache site
https://logging.apache.org/log4j/2.x/manual/configuration.html
In logging, all the objects are segregated into two major Object Types:
Core Objects: Mandatory Objects of the framework. composed of objects like Logger Object, Layout Object, Appender Object.
Support Objects: Optional Objects of the framework, but yet do important tasks. This is composed of objects as Level, Filter, ObjectRenderer, LogManager.
In this post we will see how we can customize For Pattern Objects:
Sample Example from Pega prlogging.xml file given below:
<Pattern>%d [%20.20t] [%10.10X{pegathread}] [%20.20X{tenantid}] [%20.20X{app}] (%30.30c{3}) %-5p %X{stack} %X{userid} - %m%n</Pattern>
this is the current logging pattern, we will change this as
%-6r [%t] %L %-5p %c %x - %m%n
r - meant for elapsed time
t - for thread where its logging
p-priority(info, warn, debug, etc)
c-full class name from where logging is happening
m-message
n-to enter new line
With the above format if we restart the server, to check the new format in pega log.
14752 [localhost-startStop-1] %I INFO com.pega.pegarules.generation.internal.PRGenProviderImpl [] - invokeDynamic instrumentation for inlining is enabled
14752 [localhost-startStop-1] %I INFO com.pega.pegarules.generation.internal.PRGenProviderImpl [] - Assembly Version: 762781845
Set of available logging parameter references are given in the below links, we can do play around to see how its used. some default logging parameters some are overridden for pega.
https://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/PatternLayout.html
Logging is an important component of the software development.
A well-written logging code offers quick debugging, easy maintenance, and structured storage of an application's runtime information.
By default pega had configured Log4J for logging.
Details about the components is explained in PDN link:
https://community.pega.com/knowledgebase/articles/log-customization-prloggingxml-file#capture
Log4j artchitecture you can read it from the below URL:
https://www.tutorialspoint.com/log4j/log4j_quick_guide.htm
More details of the prlogging.xml structure is well explained in the apache site
https://logging.apache.org/log4j/2.x/manual/configuration.html
In logging, all the objects are segregated into two major Object Types:
Core Objects: Mandatory Objects of the framework. composed of objects like Logger Object, Layout Object, Appender Object.
Support Objects: Optional Objects of the framework, but yet do important tasks. This is composed of objects as Level, Filter, ObjectRenderer, LogManager.
In this post we will see how we can customize For Pattern Objects:
Sample Example from Pega prlogging.xml file given below:
<Pattern>%d [%20.20t] [%10.10X{pegathread}] [%20.20X{tenantid}] [%20.20X{app}] (%30.30c{3}) %-5p %X{stack} %X{userid} - %m%n</Pattern>
this is the current logging pattern, we will change this as
%-6r [%t] %L %-5p %c %x - %m%n
r - meant for elapsed time
t - for thread where its logging
p-priority(info, warn, debug, etc)
c-full class name from where logging is happening
m-message
n-to enter new line
With the above format if we restart the server, to check the new format in pega log.
14752 [localhost-startStop-1] %I INFO com.pega.pegarules.generation.internal.PRGenProviderImpl [] - invokeDynamic instrumentation for inlining is enabled
14752 [localhost-startStop-1] %I INFO com.pega.pegarules.generation.internal.PRGenProviderImpl [] - Assembly Version: 762781845
Set of available logging parameter references are given in the below links, we can do play around to see how its used. some default logging parameters some are overridden for pega.
https://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/PatternLayout.html
Friday, March 29, 2019
Pega Exchange - Database Query Extractor
Query Extractor:
Another Tool in pega exchange. This tool is used to extract the query, which will be formed while report definition or listview or Summary view is running.
Usually you can see the sql in ReportContentPage in clipboard, with pxSQLStatementPre or pxSQLStatementPost.
pxSQLStatementPre will have table names with corresponding class name and other where conditions will be with property mentioned in the rule.
pxSQLStatementPost will have replaced class names with the corresponding table name, configured in pega Database tables. and Where condition properties are replaced with Query Strings with "?" symbol.
And in the clipboard, pyPreparedValues value list property will be there in the sequence with the values which will replace the query strings.
QueryExtractor has been developed by Pega, and they had given it for us easy use. we can download it from the below URL. It contains code archive ZIP file and the document for configuring it in your application and how to this utility can be used.
Download the Query Extractor from the below URL:
https://community1.pega.com/exchange/components/database-query-extractor
When we run this utility, it will pop up with the sql generated and Query strings replaced with the corresponding values.
So that we can get the string and directly run in the SQL databases to check what value is returned or why its taking so much time to execute it.
Download file, and extract the ZIP, "QueryExtractor.zip", and import it into your application.
Follow the steps mentioned in the document "How to use-QueryExtractor.docx"
Sample data used in our example:
pyReportName: pyInstanceList
pyReportClass: Data-Admin-Operator-ID
Steps to follow:



Note: Please let me know, if any comments need to be removed or modified. Reviewing will help us and others who are viewing this post.
Another Tool in pega exchange. This tool is used to extract the query, which will be formed while report definition or listview or Summary view is running.
Usually you can see the sql in ReportContentPage in clipboard, with pxSQLStatementPre or pxSQLStatementPost.
pxSQLStatementPre will have table names with corresponding class name and other where conditions will be with property mentioned in the rule.
pxSQLStatementPost will have replaced class names with the corresponding table name, configured in pega Database tables. and Where condition properties are replaced with Query Strings with "?" symbol.
And in the clipboard, pyPreparedValues value list property will be there in the sequence with the values which will replace the query strings.
QueryExtractor has been developed by Pega, and they had given it for us easy use. we can download it from the below URL. It contains code archive ZIP file and the document for configuring it in your application and how to this utility can be used.
Download the Query Extractor from the below URL:
https://community1.pega.com/exchange/components/database-query-extractor
When we run this utility, it will pop up with the sql generated and Query strings replaced with the corresponding values.
So that we can get the string and directly run in the SQL databases to check what value is returned or why its taking so much time to execute it.
Download file, and extract the ZIP, "QueryExtractor.zip", and import it into your application.
Follow the steps mentioned in the document "How to use-QueryExtractor.docx"
Sample data used in our example:
pyReportName: pyInstanceList
pyReportClass: Data-Admin-Operator-ID
Steps to follow:



In pxSQLStatementPost Property value will be as:
SELECT "PC0"."pyusername" AS "pyUserName" , "PC0"."pxupdatedatetime" AS "pxUpdateDateTime" , "PC0"."pxupdateopname" AS "pxUpdateOpName" , "PC0"."pyworkgroup" AS "pyWorkGroup" , "PC0"."pyaccessgroup" AS "pyAccessGroup" , "PC0"."pzinskey" AS "pzInsKey" FROM data.pr_operators "PC0" WHERE "PC0"."pxobjclass" = ? ORDER BY 2 DESC
you can see the "?" inbetween the query which will be replaced in the run time, instead of that by the using this utillity we can get it on screen itself.
Query formed will be as follows:
SELECT "PC0"."pyusername" AS "pyUserName" , "PC0"."pxupdatedatetime" AS "pxUpdateDateTime" , "PC0"."pxupdateopname" AS "pxUpdateOpName" , "PC0"."pyworkgroup" AS "pyWorkGroup" , "PC0"."pyaccessgroup" AS "pyAccessGroup" , "PC0"."pzinskey" AS "pzInsKey" FROM data.pr_operators "PC0" WHERE "PC0"."pxobjclass" = 'Data-Admin-Operator-ID' ORDER BY 2 DESC
Note: Please let me know, if any comments need to be removed or modified. Reviewing will help us and others who are viewing this post.
Sunday, March 24, 2019
How to clear node level Datapages on each node
To clear Datapage on each node in Pega PRPC:
In Pega PRPC, using data page will improve the performance of the application, but when its used as necessary way. whether if its really required for Node level or if its required for Requestor Level.
In Some applications unwantedly datapages has been used, and it will have validity of lifetime, means it wil be there till server restarts or pega destroys, when exceeding the maximum allowed now of data pages. As a result, server memory consumption will increase and it will be collected by Garbage collector.
So without disturbing the application or changing the datapage rule, we will see how we can clear the datapage daily, by running the agent, it will be bad way of design, but it will be useful for the application running in the production.
Below mentioned can be called in agent rule and to run it daily morning to clear the node and enable it in all the nodes.
Steps to clear the Datapage cache:
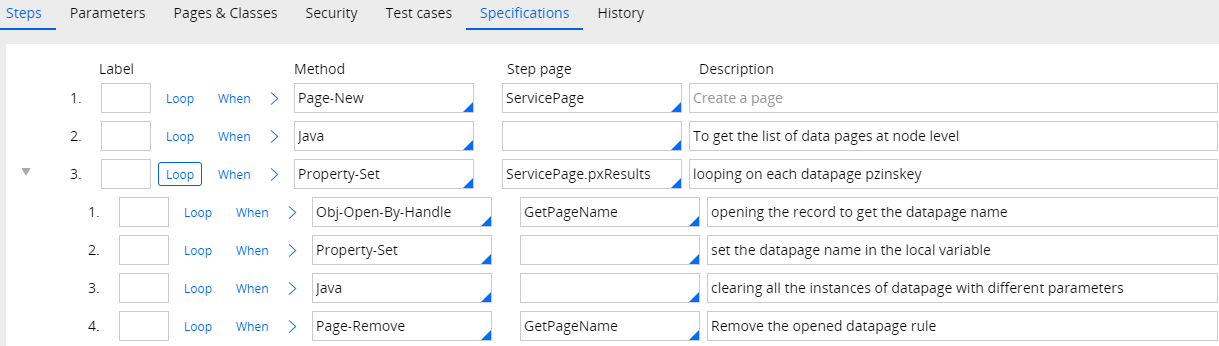
Pseudo code of the activity:



In Pega PRPC, using data page will improve the performance of the application, but when its used as necessary way. whether if its really required for Node level or if its required for Requestor Level.
In Some applications unwantedly datapages has been used, and it will have validity of lifetime, means it wil be there till server restarts or pega destroys, when exceeding the maximum allowed now of data pages. As a result, server memory consumption will increase and it will be collected by Garbage collector.
So without disturbing the application or changing the datapage rule, we will see how we can clear the datapage daily, by running the agent, it will be bad way of design, but it will be useful for the application running in the production.
Below mentioned can be called in agent rule and to run it daily morning to clear the node and enable it in all the nodes.
Steps to clear the Datapage cache:
Pseudo code of the activity:
- get the list of declare page currently in the node using engine api, which will return the pzinskey of the declare page.
- iterate on it and form Page list.
- Iterate on each page and get the declare page name
- using engine api, to clear all the instance of the declare page.
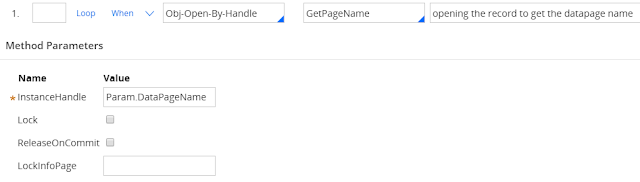
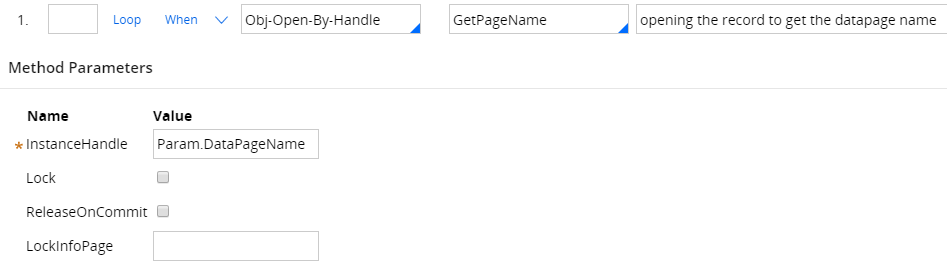
Activity screen shot are given below:
Step 1: create a page new to hold the list of datapage names, which is of class "Code-Pega-List".
Step 2: With Java method. Paste below java code there.
PRNode node = tools.getRequestor().getNode();
result1 ="Node-->"+ node.getNodeUniqueID();
java.util.Set resultSet = node.getDeclarativePageNames();
ClipboardPage ServicePage = tools.findPage("ServicePage");
ClipboardProperty pxResultProperty = ServicePage.getProperty("pxResults");
Iterator Itr=resultSet.iterator();
try{
while(Itr.hasNext()){
//ClipboardPage result2 = (ClipboardPage)Itr.next();
//String result3 = result2.getName();
String result3=(String)Itr.next();
ClipboardPage cd = tools.getThread().createPage("OCBC-Div-Unit-VISA-Work-ServiceRequest","ServicePageResults");
cd.putString("pyLabel",result3);
pxResultProperty.add(cd);
}
}
catch(Exception e){
oLog.infoForced(e);
}
Step 3: loop on page list created.


In step 4 java method:
pega.getDeclarativePageUtils().deleteAllInstancesOfDeclarativePage(result1);
In step 5: page remove method to remove the unwanted pages.
Execute the activity and see to remove the data page from the clipboard.
Note: If you have comments or corrections, please let me know, will update in the post.
Subscribe to:
Posts (Atom)